
15 Years of Data - From Closed to Open Source
It feels almost surreal to take a step back and recognize that I have now spent 15 years of my life working professionally in the field of data.
Over this time, I have experienced a monumental shift in how organizations configure their reporting platforms. What was once a field dominated by add-ons provided by corporate B2B titans like SAP, Oracle, and IBM, has evolved into a field where open source solutions provide far superior options for organizations to utilize.
In this post I’ll share some of my experiences that have coincided with that shift, while providing anecdotes of how open source tools have changed the landscape for the better. I’ll also add in my thoughts on where open source tools are going to take us over the next few years.
Industry experience in the early 2010s
My first professional job was as a “Business Intelligence Analyst” at the company Under Armour, which at the time was growing rather rapidly. Under Armour had a huge partnership with SAP to provide their technological solutions, which included not just their flagship ERP solution, but a proliferation of analytical tools as well.
I didn’t realize it at the time, but the SAP analytical tools were downright…awful. To load data, we were forced to use SAP’s own proprietary programming language ABAP, which was very poorly documented and understood. It is highly likely that we wrote poor ABAP, but given its closed nature and lack of community, there was no way to really tell.
The data extraction jobs that we wrote in this language exhibited awful performance and were horribly unstable, even by 2010 standards. The vast majority of our business critical data loads from the ERP system ran anywhere from 4-8 hours in batch every night. I would estimate that on 60-70% of the nights we had a job failure that required the on call person to wake up at 3 AM and log into the system to restart it.
If we were lucky to have data loaded, the only interface through which we could then access the data would be through a tool called Bex Analyzer. I’ll let you google images of this tool, but needless to say, it was a glorified pivot table. SAP’s solution to visualization was implemented in another product they acquired called BusinessObjects. These tools in this suite were fine at best, but, particularly for interactive visualizations, they lagged far behind a tool like Tableau, which at the time was considered first-in-class for drag and drop visualization.
Another “selling point” to using these vendor-provided tools was that we had an official support contract. Unfortunately, a support contract with a company like SAP is just a game of cat and mouse, with the ultimate goal of discouraging you as a customer from using the contract in the future. There were many instances where we would open a high priority ticket that impacted business operations. In turn, we would get connected with support “experts” who had very little knowledge of the inner workings of their tool.
The fact that the first few layers of support did not have much knowledge of the tools they supported is not an admonition of the people; rather, it is a rebuke of the closed source model where, even within an organization, only a select few are allowed to see the inner workings of a tool. The only thing initial lines of support possessed was a private collection of internal notes for common issues. Think of a site like StackOverflow, but instead of being freely accessible, you pay for someone else to have exclusive access to it and they just tell you what they see.
Of course, the notes that were collected did not cover many of the issues we would face. There were many times where we would be engaging support for multiple hours, only for the support team to say “sorry our workday has finished, we will share our findings with associates in the next time zone that will help you.” Rarely ever were findings shared, so we ended up in the support Twilight Zone until something by chance resolved itself. In extreme cases, this would take days, and really no one learned anything from it - everyone was just relieved that they could close the ticket and move on until the next one.
In all fairness to SAP, I have had similar experiences with Microsoft and their Power Platform support contracts. SAP is not unique in offering poor value in exchange for these contracts; generally, closed-source B2B enterprises can make a large amount of profit off of these contracts while offering customers very poor ROI in return. In the early 2010s, this was common practice.
The cherry on top of poor ROI would manifest itself every few years when it was time to upgrade systems. In the early 2010s many customers had to manage their stack and avoid obsolescence (cloud, PaaS, and SaaS were not yet as common as they are today).
For the proprietary reporting platform provider like SAP, this presented a great opportunity to double dip on profits. By providing customers with subpar tools and not having accountability to fix issues, the solution to many unresolved issues would be “hey, you just need to upgrade.” Upgraded software came with a licensing fee, would be bundled with resold hardware, and would require the hiring of consultants to just get you onto a more recent version of the tool. Needless to say, this process was really expensive. At times, you would have to pay millions if not more to simply avoid obsolescence. Without no alternatives, many customers had no choice but to follow down this path.
Open Source Tools to the Rescue
My first serious exposure to open source data tools was back in 2017. It was not something that was promoted by the industry I worked in, but rather a curiosity of mine that led to some awesome discoveries.
Speaking briefly to my first use case, Under Armour had no standardization as to how their vendors were packing certain types of products into boxes. That might not sound like a big deal, but it has measurable costs when boxes break, or your warehouse needs to repack goods.
The dataset I was working with was a few million records of vendor shipments, and our SAP-provided tools we had were of no use with data, even at this scale. Curiously, I fired up pandas and used the seaborn library to generate a violin plot of this data. If you don’t know what a violin plot is, here’s one that I created in my recent book, the Pandas Cookbook, Third Edition:
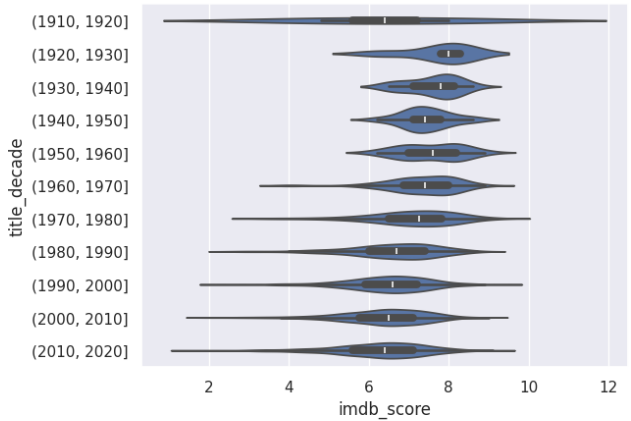
This plot shows the distribution IMDB scores across different decades, and you can rather easily see trends not only in terms of averages but with the distributions of data as well. Imagine replacing the years on the y-axis with different product types and the x-axis values with the number of units packed into a carton, and you have an idea of what I was able to visualize in Python. The fact that I could do this with freely available tools in a matter of seconds, and in a way that was highly auditable and reproducible was downright…amazing!
Shortly after I started working with open source tools in corporate settings, I moved into the world of consulting, first at a small practice and then independently. During that time, I was able to contribute back to the open source ecosystem, and in doing so felt like I stumbled upon a gold mine. The first project I contributed to was pandas (of which I am a maintainer today), and that unlocked interactions with users in scikit-learn, SciPy, NumPy, and many other great tools. I also followed a lot of the work that Wes McKinney did with his move from pandas to Apache Arrow, a project which I also became a Committer to in 2024.
The work I put into open source at this time didn’t pay the bills, but it offered me a huge network and ecosystem to work with in my consulting engagements. It also taught me best practices in software engineering, which can be translated over into data engineering to drive real scalability.
Instead of using reporting tools provided by the SAPs and Oracles of the world, the stacks I build at clients today typically use some combination of:
- Terraform, for Infrastructure as Code
- Apache Airflow, for Job Orchestration
- Python as a glue language for ETL
- dbt-core for transformations and testing
- git for version control
- Github Actions for CI/CD
…and more. At a minimum these tools are entirely free to use, but if you wanted to go more of a hosted solution route you can find many third party PaaS and SaaS providers for them. The costs of these services are very affordable compared to the reporting platforms of the early 2010s.
Perhaps the most important thing to building a stack like this is that you limit vendor lock-in. Gone are the days where a B2B provider can provide a subpar solution and charge you more money to upgrade it - you ultimately have control over how your data is managed, maintained, and evolved.
Granted, you need some degree of technical inclination to maintain, but keep in mind that these tools are being taught and used at universities, and can be used at home free-of-cost by those willing to learn. That alone is a huge advantage compared to traditional closed-source reporting architectures. Also keep in mind that as LLMs continue to become more powerful, that the amount of open information for these tools is a huge asset. You can ask popular chatbots questions about these and get much higher quality information than if you were to ask about an SAP, Oracle, or IBM closed-source tool.
Open platforms saved companies significant amounts of money. I have not seen anywhere near the amount of money invested to implement, upgrade, and maintain open source reporting platforms as compared to traditional providers. Large project implementations are reduced from tens to hundreds of millions of dollars down to less than a million.
Of course, there are still some gaps in the open source space. You may have noticed that I didn’t list a visualization platform in my tools above. With the companies I’ve partnered with, Power BI and Tableau tend to dominate that space, with Looker not far behind. Hex is a tool that I will be following closely as well, given it integrates well into the open source ecosystem, but generally there is not an open source visualization tool I know of today that can compete in this space. Open source markets itself to technical audiences, but visualization tools are a bridge for non-technical audiences into the technical world. To build a big community in that space around an open source tool might be challenging, but who knows - maybe one day it will happen.
Where are We Headed
Throughout this blog post I’ve highlighted my experiences moving from closed to open source reporting tools, and I think that has been largely reflective of the industry as a whole. However, open source reporting architecture still needs to capture more market share. From both a technical and economical perspective, I see no reason why this won’t continue, but it takes time to shift industries. If you happen to work at a company that still has not yet adopted open source tools, shoot me an email at will_ayd@innobi.io - I’d love to chat about how the right platform will drive down your operational costs and improve the value of your data.
For companies that have already adopted an open source architecture, there is still a lot that the open source community itself can do to improve interoperability. If you have followed the dataframe space for the past few years, you have seen tools like Polars, Apache DataFusion, and DuckDb work their way into a space that was once dominated by tools like pandas or R. As a maintainer of pandas, I ultimately think this choice is a good thing. Tools should be a means to an end, not the end goal of expression. Find whatever works best for you and let the open source community optimize it.
The idea that you can plug and play different open source tools into your stack is a core tenet of the “Composable Data System.” Wes McKinney and many other titans of the industry have espoused this idea in their own writing; see Wes’ own 15 year reflection and the The Composable Data Management System Manifesto.
To think about what that means non-technically, just imagine that you are a company that uses SAP’s ERP solution and Microsoft Power BI for reporting. Those are both closed source tools that implement data storage in their own ways, so every time you move data from one to the other you have to pay some kind of cost. That cost can manifest itself in compute time, data loss, or in the troubleshooting of job failures.
In the open source space, the Apache Arrow project gives all of the tools the ability to “speak the same language.” So if you have a dataframe library like pandas and want to create visualizations in a tool like Vega, there is no additional cost to using those two together. Pandas can store data in a way that Vega understands; the two communicate and operate on the same data in memory, so your ETL costs go down to zero, you have no data loss, and there becomes no job failures to troubleshoot.
Apache Arrow will continue to help a lot in terms of exchanging data. If you’ve used the Apache Parquet format for exchanging data, you have already seen this. That format in particular enables highly efficient, lossless storage between dataframe libraries, databases, and visualization tools. It drastically improved a space that struggled mightily when the de facto method of data exchange was through CSV files.
As successful as that has been, there are other methods of data exchange that can still improve, with database communication being a prime example. To that end, the Apache Arrow project has developed the Arrow Database Connectivity (ADBC) standard. While a relatively young project, it has made it immensely more efficient to exchange data between dataframes and databases like PostgreSQL, SQLite, Snowflake, and BigQuery. If you haven’t yet seen my PyData 2023 talk on ADBC - check it out. Simply put, ADBC makes it much faster, cheaper, and safer to exchange data with databases. I hope to see adoption of ADBC continue to grow with more databases in the next few years.
There’s also the ability to exchange Arrow data over HTTP, which can solve a rather significant throughput problem. In today’s world, companies often partner with a multitude of SaaS solutions that refuse to provide lower level access to their database, instead giving customers a REST API through which they can access the data. This checks the box for saying “hey we can share your data with you,” but different consumers need data shared in a different way. Usually, the data exchange mechanisms provided by SaaS solutions have been sufficient for creating reactionary web hooks, but struggle to exchange data in bulk. Reporting platforms often need the latter, so I’m hoping to see more adoption of this practice in the next few years to solve real scalability problems that companies face today.